Java 集合分 List、Set、Map 三大類,其中 List 和 Set 實現了 Collection 接口。List 的特點是數據有序、可重複;Set 的特點是數據無序、不可重複;Map 存儲鍵值映射,Key 不可重複,Value 可重複,且一個 Key 只能對應一個 Value。
List 有一實現 ArrayList,其底層實現是對象數組,默認容量是 10,但等到首次添加元素時才分配內存,每次遞增爲上次容量的 1.5 倍。在添加大量元素之前,建議調用 ensureCapacity 方法擴容,以減少遞增式再分配內存的次數。
Set 有一實現 HashSet,其底層實現是 HashMap ,其檢查重複的機制有賴於 hashCode 和 equals 方法。
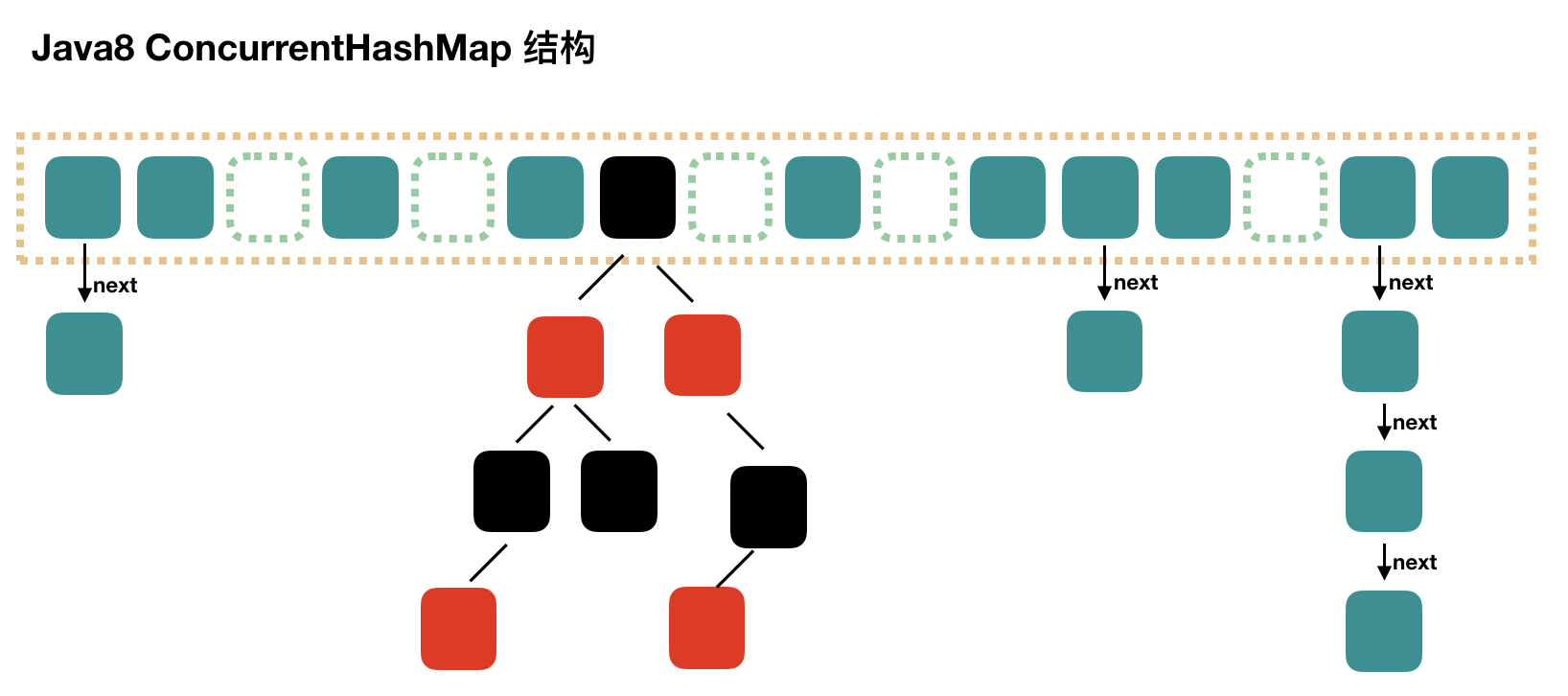
Map 有一實現 HashMap ,JDK 1.8 之後其底層實現是:數組 + 鏈表 + 紅黑二叉樹。紅黑樹是爲了減少搜索時間,默認當鏈表長度大於 8 且當前數組長度大於等於 64 時,鏈表會轉爲紅黑樹。數組默認容量是 16,通過帶參構造方法傳入的容量值如非 2 的幂次會自動向上轉爲 2 的幂次,以便元素散列存儲(元素位置才可通過 hash & (length-1) 確定)。添加元素時,若元素數量大於數組長度的 75% 且該元素存在哈希衝突,則觸發擴容機制,數組容量翻倍。
總結下 HashMap 中解決哈希衝突的方式:
- 使用鏈表 — 拉鍊法;
- 使用紅黑二叉樹;
- 擴容底層數組;
- 強制數組容量爲 2 之幂次;
- 將元素的 hash 值的高位分散到低位等等。
ArrayList、HashSet、HashMap 都是線程不安全的。在多線程環境下應使用 J.U.C 包下的對應的並發類 CopyOnWriteArrayList 、ConcurrentHashMap (HashSet 用ConcurrentHashMap 的 keySet 可得 Set 視圖)。CopyOnWriteArrayList 會在寫時加鎖並複製集合進行操作;ConcurrentHashMap 在 JDK 1.7 使用分段鎖,在 JDK 1.8 取消分段鎖採用 CAS(樂觀鎖) 和 synchronized(悲觀鎖) 只對鏈表或紅黑二叉樹的節點加鎖。
概覽
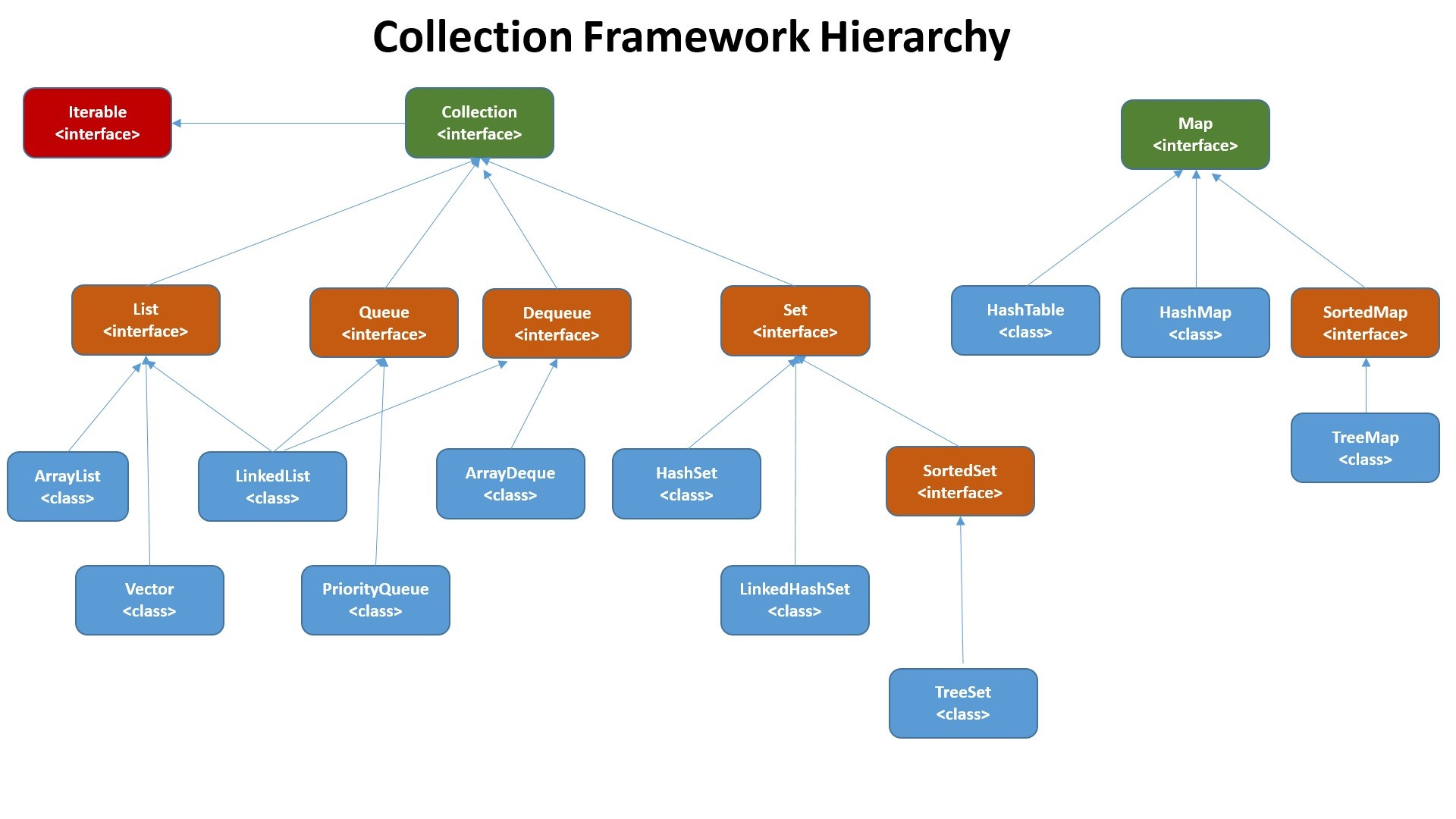
集合是相對數組來說,更靈活多樣的容器。Java 的集合框架肇始於兩大接口,Collection 和 Map。Collection 下有 List、Queue 和 Set 等等接口,然後衍生出 ArrayList、LinkedList、HashSet、TreeSet、LinkedHashSet 等等實現;Map 下有 HashMap、TreeMap 等重要子類。
List、Set、Map 三者之區別
- List:存儲的元素有序、可重複。
- Set:存儲的元素無序、不可重複。
- Map:使用鍵值對存儲,一鍵一值,Key 無序、不可重複;Value 無序、可重複。
List、Set、Map 三者之底層數據結構
- List
- ArrayList:Object 數組
- Vector:Object 數組
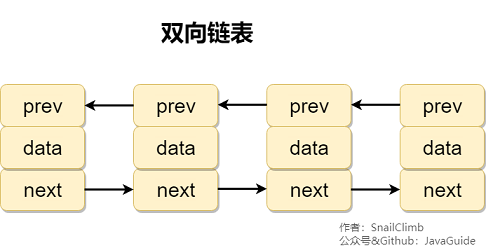
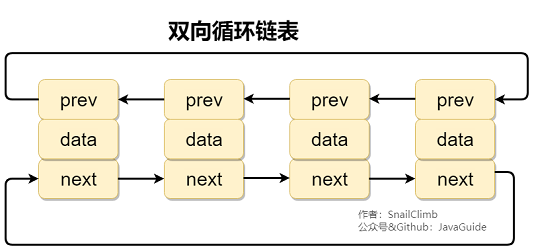
- LinkedList:雙向鏈表(JDK 1.6 之前爲循環鏈表)
- Set
- HashSet(無序、唯一):基於 HashMap
- LinkedHashSet:基於 LinkedHashMap
- TreeSet(有序、唯一):紅黑樹(自平衡的排序二叉樹)
- Map
- HashMap:數組 + 鏈表 + 紅黑樹(鏈表長於閾值即轉爲紅黑樹以減少搜索時間;閾值默認爲 8;JDK 1.8 之前沒有紅黑樹)
- LinkedHashMap:繼承自 HashMap,但多了一條雙向鏈表
- Hashtable:數組 + 鏈表
- TreeMap:紅黑樹(自平衡的排序二叉樹)
Iterator 迭代器
迭代器就是 Iterator 接口,它抽象出迭代一個集合需要的方法,hasNext() 和 next() 方法,以便集合類實現該接口,從而方便對集合的遍歷。有了迭代器就可以在迭代集合元素時更改元素而不拋出 ConcurrentModificationException 了。
爲什麼?因爲非採用 Iterator 進行遍歷時更改元素會修改到 modCount 變量(用於紀錄集合結構性改變的次數)的值,而沒有修改 expectedModCount 的值,基於 fail-fast 機制檢查兩值是否相同時會拋出異常;而使用 Iterator 遍歷時更改元素會同時修改 modCount 和 expectedModCount,兩者相等,不會拋出異常。
Map<Integer, String> map = new HashMap(); |
有哪些集合是線程不安全的?怎麼解決?
常用的 ArrayList、LinkedList、HashMap、HashSet、TreeSet、TreeMap、PriorityQueue 都不是線程安全的。解決方法就是用 java.util.concurrent 包提供的線程安全的集合來代替:
ConcurrentHashMap代替HashMap;CopyOnWriteArrayList代替ArrayList;ConcurrentLinkedQueue代替LinkedList;BlockingQueue接口下的PriorityBlockingQueue、LinkedBlockingQueue等阻塞隊列代替PriorityQueue等;ConcurrentSkipListMap代替TreeMap,實現多線程下保證按 Key 的順序存儲元素。
length、length()、size() 三者用途
length:用於數組。length():用於字符串。size():用於集合。
Collections 工具類的使用
排序
//反轉
void reverse(List list)
//隨機排序
void shuffle(List list)
//按自然排序的升序排序
void sort(List list)
//定制排序,由Comparator控制排序邏輯
void sort(List list, Comparator c)
//交換兩個索引位置的元素
void swap(List list, int i , int j)
//旋轉。當distance為正數時,將list後distance個元素整體移到前面。當distance為負數時,將 list的前distance個元素整體移到後面
void rotate(List list, int distance)查找替換統計
//對List進行二分查找,返回索引,注意List必須是有序的
int binarySearch(List list, Object key)
//根據元素的自然順序,返回最大的元素。 類比int min(Collection coll)
int max(Collection coll)
//根據定制排序,返回最大元素,排序規則由Comparatator類控制。類比int min(Collection coll, Comparator c)
int max(Collection coll, Comparator c)
//用指定的元素代替指定list中的所有元素
void fill(List list, Object obj)
//用新元素替換舊元素
boolean replaceAll(List list, Object oldVal, Object newVal)
//統計元素出現次數
int frequency(Collection c, Object o)
//統計target在list中第一次出現的索引,找不到則返回-1,類比int lastIndexOfSubList(List source, list target)
int indexOfSubList(List list, List target)
List
比較 ArrayList 與 LinkedList
共同點:
- 都實現了 List 接口;
- 都是不同步的,不保證線程安全。
不同點:
- 底層數據結構不同。ArrayList 是對象數組;LinkedList 是雙向鏈表(JDK 1.6 之前爲循環列表)。
- 插入和刪除的時間複雜度不同。ArrayList 追加元素的複雜度爲 O(1),指定位置 i 插入或刪除元素的複雜度爲 O(n-i);LinkedList 追加元素和刪除末端元素的時間複雜度爲 O(1),指定位置 i 插入或刪除元素的時間複雜度近似 O(n)。
- 對快速隨機訪問的支持不同。ArrayList 支持快速隨機訪問;LinkedList 不支持。
- 對空間的利用不同。ArrayList 末尾會預留一定的空間以便元素新增;LinkedList 則是會在每個元素多存儲了指針數據。
比較雙向鏈表與雙向循環鏈表
ArrayList 擴容機制
ArrayList 底層是對象數組,其容量可以動態增長。在添加大量元素之前,建議調用 ensureCapacity 方法擴容,以減少遞增式再分配內存的次數,提升程序效率。
其擴容機制大致是這樣的:ArrayList 提供了默認構造方法,通過默認構造方法構造對象,默認容量值爲 10 ,但此時未分配相應內存空間,而是等到首次添加元素時才開始初始化一個空間爲 10 的對象數組。當第 11 個元素加入時會觸發擴容機制,容量會擴充到原來的 1.5 倍(newCapacity = oldCapacity + oldCapacity >> 2),即變爲 15。如通過指定相應的容量大小的構造方法構造對象且指定的容量值大於 0 ,則一開始就會分配相應的內存空間。
快速隨機訪問 RandomAccess
RandomAccess 接口爲空實現,僅僅標識著實現類具備快速隨機訪問的能力。ArrayList 實現了該接口,而 LinkedList 未實現。
public interface RandomAccess { |
System.arraycopy() 與 Arrays.copyOf() 方法
System.arraycopy()方法用於源數組到目標數組之間的數據拷貝;Arrays.copyOf()方法用於給源數組擴容,底層調用System.arraycopy()。
CopyOnWriteArrayList 的特點
- 寫時會加鎖並複製整個集合;
- 讀時可能讀到舊數據。
如何移除列表中的元素
首先,不能在 foreach 循環中移除元素,根據 fail-fast(快速失敗) 機制,會拋出 ConcurrentModificationException (並發修改異常)。
可以採用 iterator 或者 Collection.removeIf() 方法移除列表元素。
String[] arrs = {"a", "b", "c"}; |
正確使用 Arrays.asList
如果非要在 foreach 循環中刪除元素,還可以使用 CopyOnWriteArrayList,此集合是 fail-safe 的。CopyOnWriteArrayList 修改元素時會 copy 一個新列表進行修改,不會改變迭代中的列表,因此是安全的,但會產生新的列表作爲代價。
Arrays 工具類有一個靜態方法 asList(T... a),能將對象數組包裝成一個 List,底層數據依然是原數組,原數組改變,List 也隨之改變,但 List 本身的 add/remove/clear 並不可用,調用會拋出 UnsupportedOperationException。
Arrays 類中關於 asList 方法的代碼如下:
public static <T> List<T> asList(T... a) { |
爲什麼 asList 方法傳入的必須是對象數組呢?
你看上面的代碼,泛型,沒錯泛型只能是對象啊,基本類型是不行的。
傳入基本類型的數組會怎樣呢?請看下面代碼:
int[] ints = {1, 3, 4}; |
把數組轉爲 java.util.ArrayList
那麼,如何簡便地把一個數組轉爲普遍意義上的 ArrayList 呢?
// 1) 使用 ArrayList 的帶參構造方法 |
將 List 轉爲數組
使用 List 的 toArray 方法可以將 List 轉爲數組,代碼如下:
// new String[0] 僅僅爲了告知類型返回數組的類型 |
Set
無序性和不可重複性的含義
無序性並不等同於隨機性,而是根據數據的哈希值決定其存儲位置,使用者無法指定其存儲順序。
不可重複性是指添加的元素按 equals 方法判斷結果爲 false。
比較 HashSet、LinkedHashSet 和 TreeSet
共同點:
- 都實現了 Set 接口;
- 元素不可重複;
- 都是線程不安全的。
不同點:
- 底層數據接口不同。HashSet 底層是 HashMap;LinkedHashSet 底層是 LinkedHashMap;TreeSet 底層是紅黑樹。
- 有序性不同。HashSet 無序;LinkedHashSet 和 TreeSet 有序。TreeSet 還可以自定義排序。
自定義排序的實現
自定義排序最通用的就是給要排序的類實現一個 Comparable 接口,隨後可以使用 Collection.sort 方法進行排序。又或者不實現 Comparable 接口,而是傳入 Comparator 到 Collection.sort 方法中。
HashSet 如何檢查重複
HashSet 集合進行元素重複校驗時先比較 hashcode ,當 hashcode 一樣時再調用 equals,提高了校驗效率。因此,如果只重寫 equals 方法而不重寫 hashcode 方法,會出現 equals 返回 true,而 hashcode 不等的情況,這樣如果要求 HashSet 去重就會失敗。
Map
比較 HashMap 與 TreeMap
共同點:
- 都繼承自 AbstractMap,間接實現了 Map 接口;
- 都是線程不安全的。
不同點:
- 底層數據結構不同。HashMap 底層是數組 + 鏈表 + 紅黑樹(鏈表長於閾值即轉爲紅黑樹以減少搜索時間;閾值默認爲 8;JDK 1.8 之前沒有紅黑樹);TreeMap 底層是紅黑樹。
- HashMap 無搜索和排序的能力。TreeMap 實現了 NavigableMap 接口,使其有對集合內元素搜索的能力;實現了 SortMap 接口,使其有對集合內元素根據鍵排序的能力。
HashMap 底層實現
JDK 1.7 或之前,HashMap 的底層實現是數組+鏈表。該數組的定義如下:
transient Node<K,V>[] table; |
Node 存儲了鍵、值、哈希值和下一個節點,是一個鏈表,也就是說 Node 數組就是一個鏈表數組。
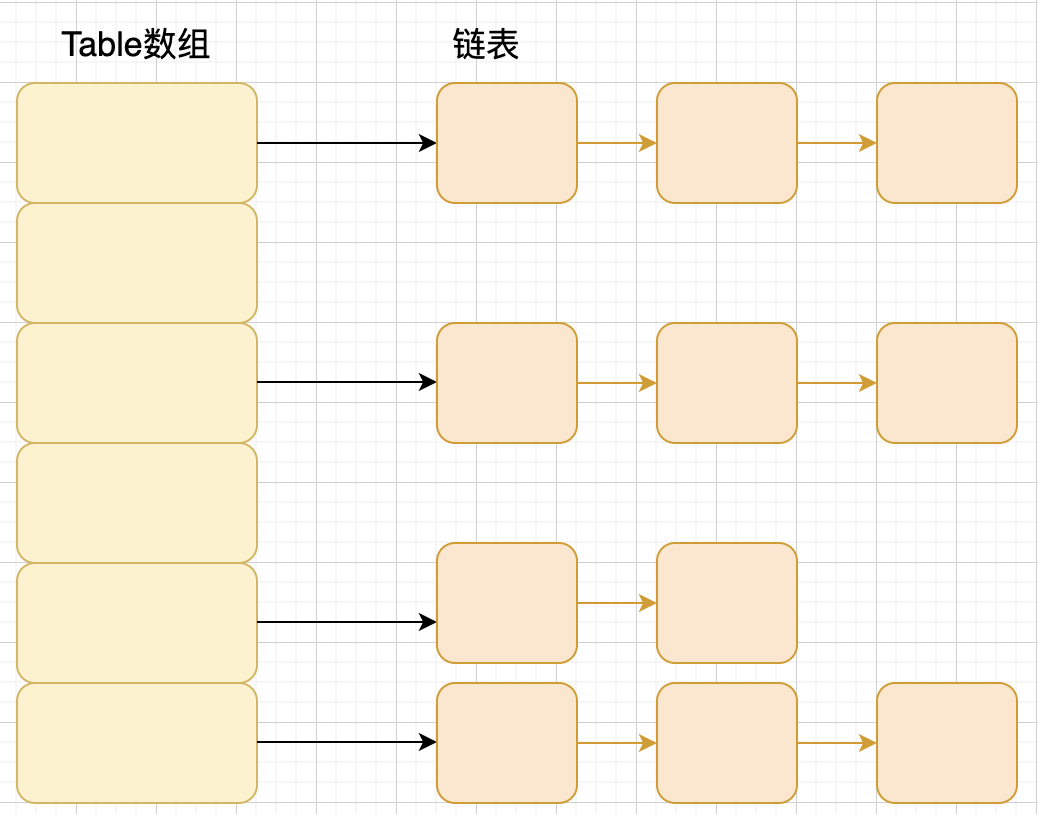
該數組默認大小是 1 << 4 = 16 。調用 put 方法增加元素時,通過散列算法(hash方法,也稱之爲擾動函數)算得元素的 hash 值,然後計算其應插入的桶(數組中的一個位置)。如果該位置已有元素,就會產生哈希衝突(或稱碰撞),此時通過拉鍊法解決。當 Map 中包含的元素數量大於等於 threshold = loadFactor * capacity (loadFactor 默認爲 0.75f),且新建的元素剛好落在一個非空的桶上時,會觸發擴容機制,將數組容量擴大 2 倍。
JDK 1.8 開始,HashMap 的底層實現是數組+鏈表+紅黑樹,當鏈表長度大於閾值(默認爲 8),且當前數組長度大於等於 64 時,該鏈表會轉爲紅黑樹,以減少搜索時間。
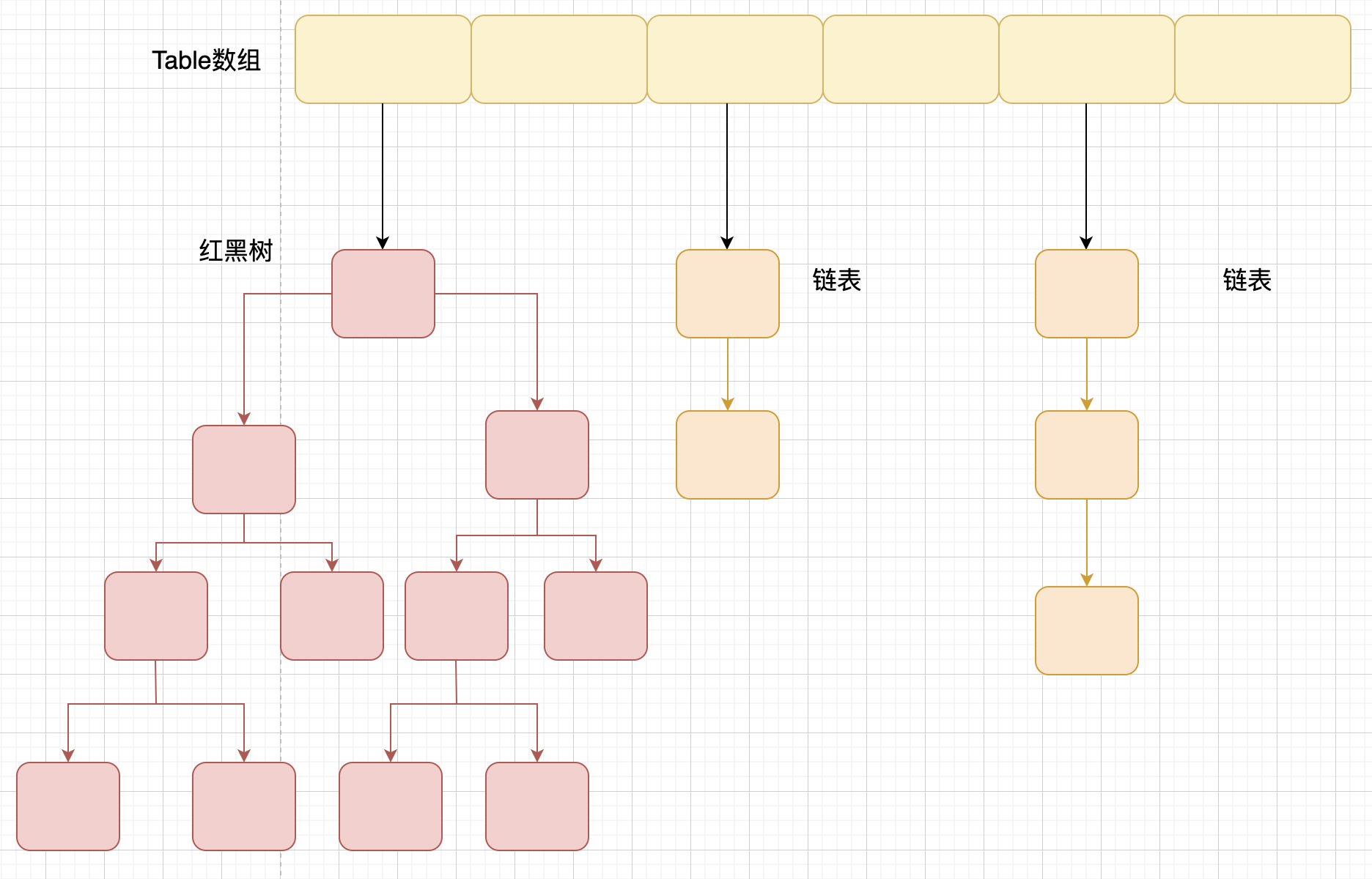
(1)散列算法
首先獲取 key 的 hash 值,然後將高位的 hash 分散到低位,以便減少哈希衝突。
// JDK 1.7 |
(2)插入算法
如何根據散列值確定要插入的數組位置呢?因爲保證了數組長度爲 2 之幂次,所以確定插入位置時的取餘算法 hash % length 等價於 h & (length-1)。簡單起見,假定 hash 爲 0100 1010; length 是 8,其二進制爲 0000 1000,取餘爲 hash % length = 0000 0010 = h & (length-1)。此處 hash 值的高位 0100 並沒有用到,會造成高位不同而低位相同的 hash 值衝突,這也是散列算法要將高位分散到低位的緣故。
/** |
(3)拉鍊法
將衝突的值加到鏈表中。
(4)保證數組長度爲 2 之幂次的方法
方法一(JDK 1.8 或以前):將原數二進制表示的第一個非零位後面的所有零位填滿爲 1,然後再加 1。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}方法二(JDK 15):計算原數二進制表示的第一個非零位前面零的數量 k,然後將 -1 (其二進制形式全是1)無符號右移 k 位再加 1。
// HashMap.java
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// Integer.java
// 取得整數二進制表示前面的零位數量
public static int numberOfLeadingZeros(int i) {
// HD, Count leading 0's
if (i <= 0)
return i == 0 ? 32 : 0;
int n = 31;
if (i >= 1 << 16) { n -= 16; i >>>= 16; }
if (i >= 1 << 8) { n -= 8; i >>>= 8; }
if (i >= 1 << 4) { n -= 4; i >>>= 4; }
if (i >= 1 << 2) { n -= 2; i >>>= 2; }
return n - (i >>> 1);
}方法三(不推薦):將原數以 2 爲底取對數,然後再取其 ceil 值,將其作爲 2 的指數計算即可。
int n = (int) Math.pow(2, (int) Math.ceil(Math.log(cap) / Math.log(2)));
遍歷 HashMap 的幾種方式
HashMap 有四大類遍歷方式:iterator、for、lambda 和 stream。性能上 stream 的並行循環最高,其他的差別不大。安全性上在遍歷時應使用 iterator.remove方法刪除元素或者用 stream 的 filter 過濾不需要的數據再進行循環。參見 https://mp.weixin.qq.com/s/Zz6mofCtmYpABDL1ap04ow
Map<String, String> map = new HashMap<>(); |
ConcurrentHashMap 線程安全的原因
我們知道 HashMap 是線程不安全的,在多線程環境下需要用 ConcurrentHashMap 代替。那麼,ConcurrentHashMap 是怎麼實現線程安全的呢?
JDK 1.7 時,採用分段鎖,主幹是一個 Segment 數組,Segment 裏維護著一個 HashEntry 數組。對同一 Segment 的數據進行操作需要考慮鎖競爭,不同的則不需要。
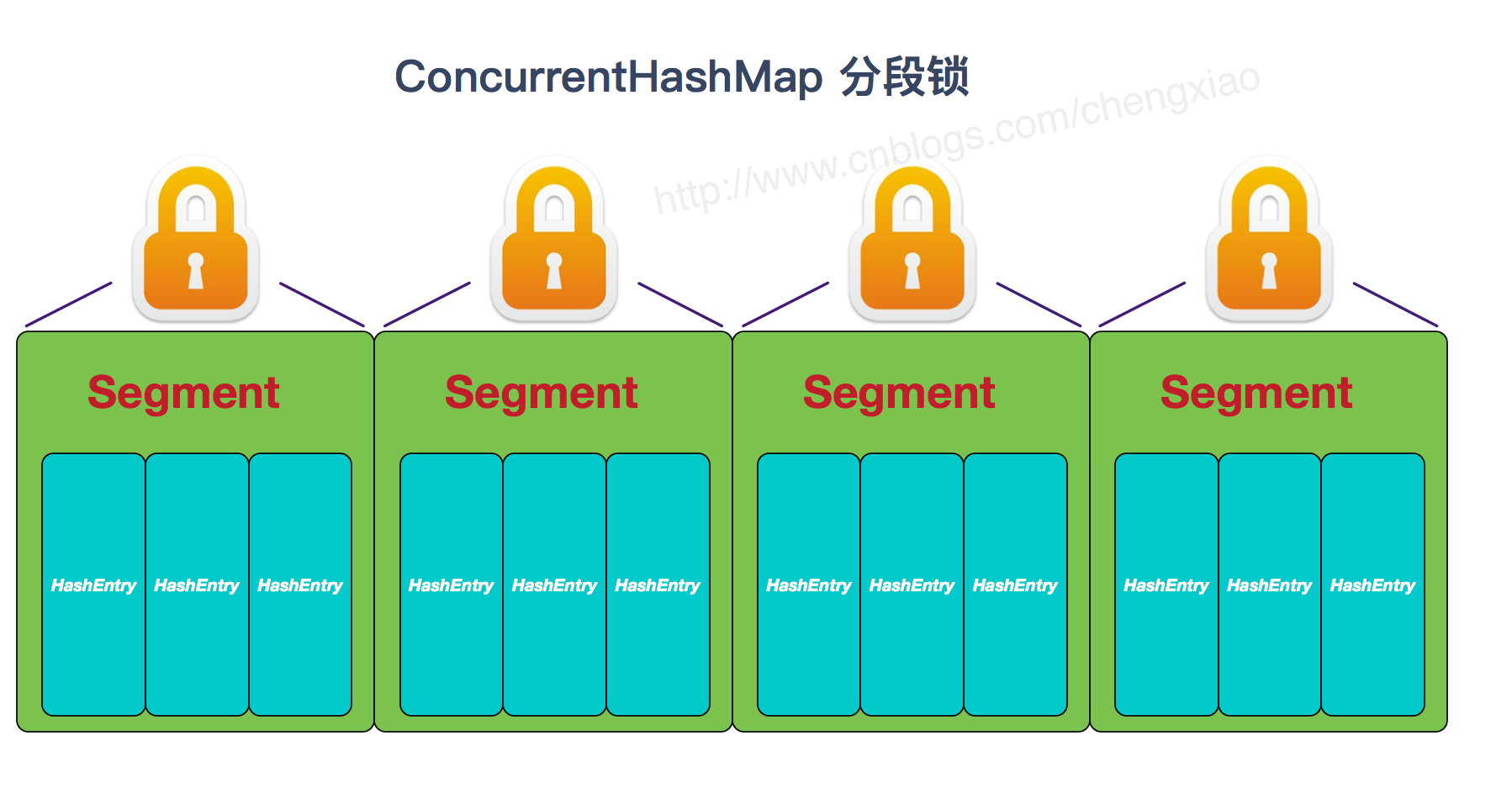
JDK 1.8 開始取消了分段鎖,採用 CAS(樂觀鎖) 和 synchronized(悲觀鎖) 來保證並發安全。synchronized 只鎖定當前鏈表或紅黑二叉樹的首節點,這樣只要 hash 不衝突,就不會產生並發。