編譯原理這一章講 Go 的源代碼是如何變成二進制碼的,可分爲四個過程:
- 詞法和語法分析 lexical and grammar analysis
- 類型檢查 type check
- 中間代碼生成 IR(intermediate representation) generation
- 機器碼生成 machine code generation
詞法分析是將源代碼視爲字符串序列,對各個字符串進行標記,生成 Token 序列。
語法分析是將 Token 序列按照 LALR(1)(向前查看和自底向上解析)的解析文法進行解析,生成一棵AST (抽象語法樹 )。
類型檢查分靜態類型檢查和動態類型檢查,靜態類型檢查會在編譯期對變量賦值、返回值和函數參數進行類型檢查;動態類型檢查在代碼運行時進行,可以實現向下類型轉換、延遲綁定和反射等功能。
中間代碼生成階段首先會進行 ssaconfig 的初始化,緩存可能需要用到的類型和指針;然後進行遍歷和替換,將內建函數 make、map、channel、new、select、panic、recover 等等替換成 runtime 包的函數。最後不斷地進行中間代碼生成,優化代碼,生成類似彙編代碼的代碼。
機器碼生成階段分兩個部分:一是 SSA 中間代碼降級、針對特定CPU架構的中間代碼優化和重寫,最後生成相當接近特定架構彙編代碼的指令;二是將特定架構的指令轉成二進制代碼。
2.1 概述
編譯原理就是講編譯器如何將代碼編譯成二進制碼。
2.1.1 預備知識
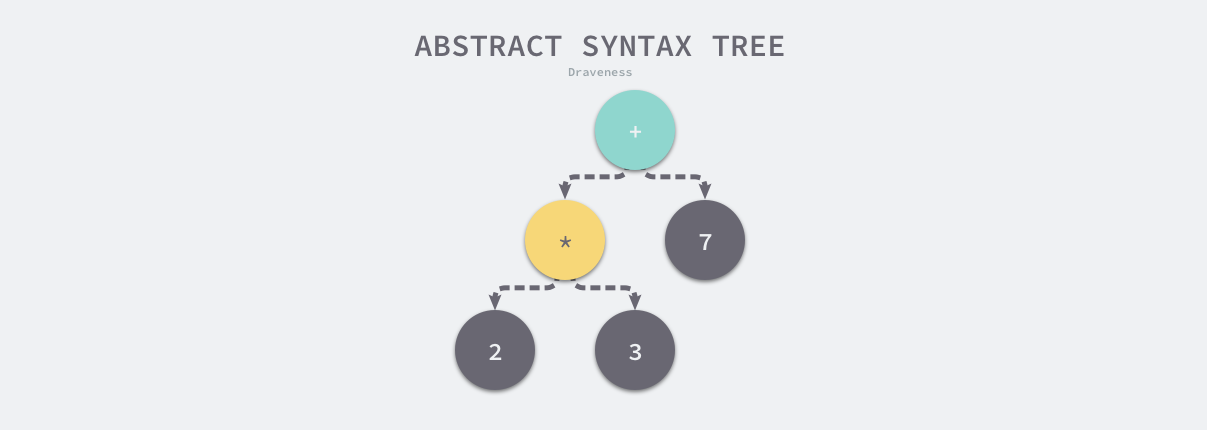
(1)抽象語法樹
抽象語法樹(Abstract Syntax Tree、AST),是源代碼語法的結構的樹狀表示。以表達式 2 * 3 + 7 為例,編譯器的語法分析階段會生成如下圖所示的抽象語法樹:
(2)靜態單賦值
靜態單賦值(Static Single Assignment、SSA),是指中間代碼每個變量只會被賦值一次。例如以下代碼:
x := 1 |
其中間的代碼爲:
x_1 := 1 |
由於 x_1 := 1 沒有什麼用,因此會在生成機器碼時省去。
(3)指令集
指令集或者說指令集架構 (Instruction set architecture, ISA),就是計算機的抽象模型。指令集可分爲兩大類:
- 複雜指令集計算機 (complex instruction set computer, CISC):包含了很多特定的指令,但是其中的一些指令很少會被程序使用(據說有 80% 不經常使用)。例如:Intel 8080、x86-family。
- 精簡指令集計算機 (reduced instruction set computer, RISC):只實現了經常被使用的指令,不常用的操作都會通過組合簡單指令來實現。例如:ARM、Power ISA。
2.1.2 編譯原理
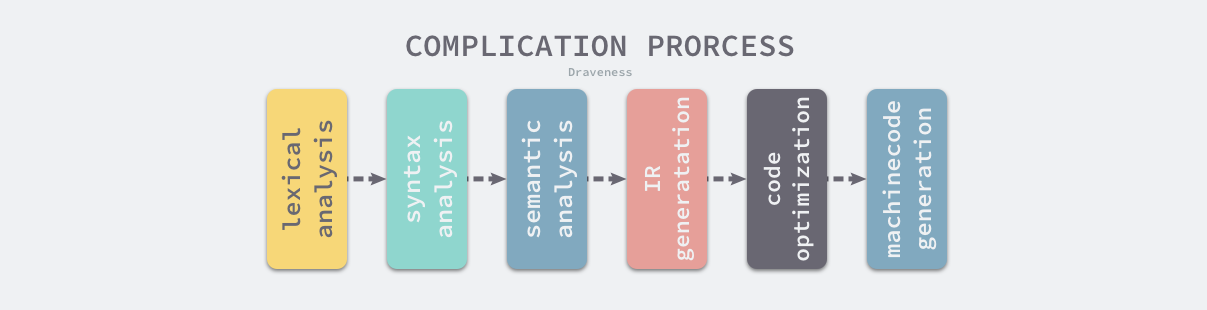
編譯器的前端:
- 詞法分析 lexical analysis
- 語法分析 syntax analysis
- 語義分析 semantic analysis
編譯器的後端:
- 中間代碼生成 IR(Intermediate Representation) generation
- 代碼優化 code optimization
- 機器碼生成 machinecode generation
Go 的編譯器邏輯上可以分爲四個階段:
- 詞法和語法分析,將源代碼字符串序列轉成 Token 序列,再轉成抽象語法樹。
- 類型檢查,檢查類型,並展開內建的函數。
- 中間代碼生成,使用 goroutine 並發生成中間代碼,並進行 SSA 優化。
- 機器碼生成,根據不同類型的 CPU 生成不同的機器碼
Go 的編譯器入口在 src/cmd/compile/internal/gc/main.go 文件中,其中的 Main 函數就是編譯器的主要程序,其工作過程是:
- 獲取命令行傳入的參數並更新編譯選項和配置。
- 調用 parseFiles 方法解析輸入的文件,得到 AST,隨後進行以下 9 個步驟:
- const, type, and names and types of funcs(檢查常量、類型以及函數的名稱和類型)
- Variable assignments(處理變量賦值)
- Type check function bodies(對函數體進行類型檢查)
- Decide how to capture closed variables(決定如何捕獲封閉的變量)
- Inlining(處理內聯函數)
- Escape analysis(進行逃逸分析)
- Transform closure bodies to properly reference captured variables(將閉包的主體轉成實際引用的捕獲變量)
- Compile top level functions(編譯頂層函數)
- Check external declarations(檢查外部聲明)
2.2 詞法和語法分析
2.2.1 詞法分析
詞法分析就是將源代碼的字符串序列轉成標記(Token)序列的過程。如 make(chan int) 經過詞法分析後是一個由 make 、(、chan、int 和 ) 組成的 Token序列。
可以使用 lex 工具進行詞法分析,Go 早期也是使用該工具,該案例展示了使用 lex 工具進行詞法分析。後期更換成了自身,該案例展示了使用 Go 自帶的詞法分析器進行詞法分析。
2.2.2 語法分析
語法分析是根據某種特定的形式文法(Grammar)對 Token 序列構成的輸入文本進行分析並確定其語法結構的過程。
文法
上下文無關文法(context-free grammar) 是用來形式化、精確描述某種編程語言的工具,由以下四個部分組成:
- N, 有限個非終結符的集合
- Σ, 有限個終結符的集合
- P, 有限個生成規則(production rule)的集合
- S, 開始變量或符號,用來代表整個語句或程序,是集合N的成員。
非終結符可以使用一組終結符根據生成規則展開,而終結符是語言定義的基本元素,不可展開。
P = N x (NvΣ)* 即生成規則是集合 N與集合N、Σ的併集的 Kleene 操作之間的二元關係。
假定有以下生成規則:
- S —> aSb // S 可以展開爲 aSb
- S —> ab // S 可以展開爲 ab
那麼,aabb(運用一次規則1,一次規則2)、aaabbb(運用兩次規則1,一次規則2)等就是符合語法規則的表示。
解析方法
解析文法的方法有兩種:
- 自頂向下解析(Top-down parsing):從最高級別開始解析,不斷地用生成規則右側的符號展開非終結符,直到最低級別的終結符號。
- 自底向上解析(Bottom-up parsing):從最低級別開始解析,不斷地用生成規則左側非終結符歸約,直到最高級別的開始符號。
LL文法是一種使用自頂向下解析的文法。假定有 LL文法如下:
- 𝑆→𝑎𝑆1
- 𝑆1→𝑏𝑆1
- 𝑆1→𝜖
輸入流 abb 採用上面的文法進行解析,其過程爲:
- S (開始符號)
- aS1(規則 1)
- abS1 (規則 2)
- abbS1 (規則2)
- abb(規則 3)
LR(0) 文法是一种使用自底向上解析的文法。假定有 LR(0) 文法如下:
- 𝑆→𝑆1
- 𝑆1→𝑆1𝑏
- 𝑆1→𝑎
輸入流 abb 採用上面的文法進行解析,其過程爲:
- a(入棧)
- S1(規則3)
- S1b(入棧)
- S1(規則2)
- S1b(入棧)
- S1(規則2)
- S(規則1)
當有多個生成規則符合時,會出現衝突。解析時可以採用 Lookahead 向前查看技術解決,即預讀一個 Token 確保出現衝突的生成規則可以被正確處理。
Go 語言的解析器採用 LALR(1) 的文法進行解析,是一種自底向上且帶有 Lookahead(縮寫爲LA) 功能的解析文法。LALR(1) 也是大多數編程語言的選擇。
Go 文法
閱讀 src/cmd/compile/internal/syntax/parser.go,可知:
每個 Go 源代碼文件最終都會被解析成一個獨立的抽象語法樹,所以語法樹最頂層的結構或者開始符號都是 SourceFile:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } . |
PackageClause 的生成規則爲:
PackageClause = "package" PackageName . |
ImportDecl 的生成規則爲:
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) . |
TopLevelDecl 的生成規則爲:
TopLevelDecl = Declaration | FunctionDecl | MethodDecl . |
可知頂層的聲明共有五種,分別是常量、類型、變量、函數和方法聲明,其生成规则如下:
ConstDecl = "const" ( ConstSpec | "(" { ConstSpec ";" } ")" ) . |
更詳細的文法見:Language Specification。
2.3 類型檢查
類型檢查的目的在於確保代碼正確執行。
類型分兩種:強類型和弱類型。一般來說,強類型是在編譯期間有嚴格的類型限制,會在編譯期間發現變量賦值、返回值和函數調用是的類型錯誤。弱類型則是在運行時出現類型錯誤時進行隱式類型轉換。
檢查也分兩種:靜態類型檢查和動態類型檢查。靜態類型檢查是在編譯期進行,動態類型檢查是在運行期間進行。實現動態類型檢查通常是爲每個運行時對象關聯一個類型標籤,包含了它的類型信息(RTTI, the Runtime type information),用來實現動態派發、延遲綁定、向下轉型和反射等等。
另外,只使用動態類型檢查的編程語言叫做動態類型編程語言,比如 JavaScript、Ruby 和 PHP。
Go 進行靜態類型檢查的代碼主要邏輯在 cmd/compile/internal/gc.typecheck 和 cmd/compile/internal/gc.typecheck1 中。
func typecheck1(n *Node, top int) (res *Node) { |
介紹幾種常見類型的檢查過程:
- OTARRAY 數組或切片類型:
- 對右節點也就是元素進行類型檢查
- 對左節點,按三種情況:
- []int,直接調用 cmd/compile/internal/types.NewSlice,返回一個
TSLICE類型的結構體。 - […]int,ODDD(即…) 先調用 cmd/compile/internal/gc.typecheckcomplit ,後調用 cmd/compile/internal/types.NewArray 初始化一個存儲著數組中元素類型和數組大小的結構體。
- [3]int,調用 cmd/compile/internal/types.NewArray 初始化一個存儲著數組中元素類型和數組大小的結構體。
- []int,直接調用 cmd/compile/internal/types.NewSlice,返回一個
- OTMAP 哈希類型:
- 分別檢查鍵值類型
- 通過 cmd/compile/internal/types.NewMap 创建一个新的 TMAP 结构并将哈希的键值类型都存储到该结构体
- 代表當前哈希的節點最終也會被加入 mapqueue 隊列,編譯器會在後面的階段對哈希鍵的類型進行再次檢查。
- OMAKE 內置函數make
- 檢查第一個類型參數,然後據此進入不同的分支:TSLICE 切片分支、TMAP 哈希分支和 TCHAN 信道分支。
- 如是 TSLICE 分支,將檢查 len 和 cap 的合法性,然後將當前節點的 Op 改爲 OMAKESLICE。
- 如是 TMAP 分支,將在檢查 size 之後將當前節點的 Op 改爲 OMAKEMAP。
- 如是 TCHAN 分支,將在檢查 buffer 之後將當前節點的 Op 改爲 OMAKECHAN。
2.4 中間代碼生成
中間代碼生成是爲了解決直接編譯成二進制碼的複雜。通過將複雜問題拆分成一個個簡單的步驟,再逐個擊破,這就是中間代碼的作用。
AST 和二進制碼之間隔了幾十次中間代碼的生成。生成之初會將緩存可能需要用到的類型和指針,並將內建函數映射到 runtime包中的函數。之後每次中間代碼的生成都是對代碼的優化,最後生成具備 SSA 特性的中間代碼。

關鍵字和操作符和運行時函數的映射
中間代碼不是彙編代碼,但是很接近彙編代碼,也用到一些寄存器,可說是彙編代碼的偽代碼(pseudo code),中間代碼形如:
pass trim begin |
2.5 機器碼生成
機器碼的生成包含兩個部分:
- cmd/compile/internal/ssa 進行 SSA 中間代碼的降級過程,執行架構特定的優化和重寫,最後生成架構特定的指令 cmd/compile/internal/obj.Prog。
- cmd/internal/obj 作爲彙編器將架構特定的指令轉成二進制代碼。